Tracking Task¶
The tracking task is very similar to the Detection Task, but instead of all objects being static, they move around the environment.
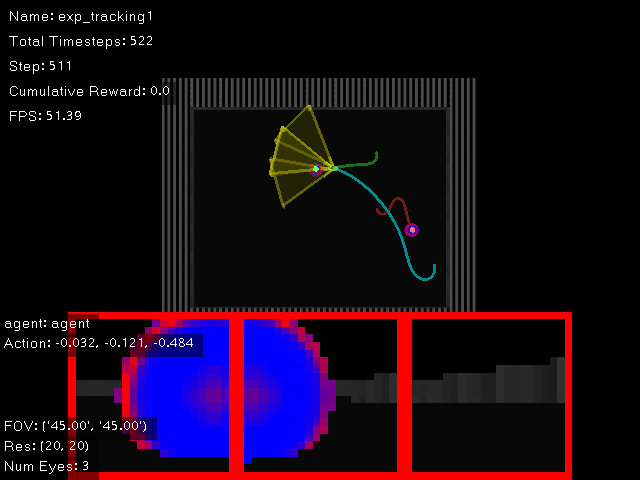
Screenshot of the tracking task. Similar to the Detection Task, the tracking task implements a simple control for the objects. Each object will move to random positions within the map, their movement visualized by the green and red trails. The agent thus must learn to discern between the strips like in the detection task, but also track the objects as they move.¶
The reward function for the tracking task is identical to the detection task.
\(R_{\text{Tracking}}\) is the reward at time \(t\) for each task, \(\lambda\) is a scaling factor, \(x_t\) and \(x_{t-1}\) is the position of the agent at time \(t\) and \(t-1\) respectively, \(x_0\) is the initial position of the agent, and \(x_f\) is the position of the goal. The \(w\) variables are non-zero when certain conditions are met. \(w_g\) and \(w_a\) indicates the reward/penalty given for reaching the goal and adversary, respectively. \(w_c\) is the penalty for contacting a wall. In essence, the agent is incentivized to navigate to the goal as quickly as it can. During training, \(\lambda = 0.25\), \(w_g = 1\), \(w_a = -1\), and \(w_c = -1\). Additionally, when an agent reaches the goal or adversary, the episode terminates.
Training/Evaluation/Evolving an Agent¶
The training, evaluation, and evolution of an agent for the tracking task is identical to the detection task. Please refer to the Detection Task for more information.
Below is an example of a successfully trained agent on the tracking task:
Below is an example of a privileged agent evaluation on the tracking task:
Task Configuration¶
# @package _global_
# This task is for tracking of an object. It's similar to detection, but the object(s)
# move.
defaults:
# Inherit the config from detection
- detection
# Override the goal and adversary, which both move around the map
- override /env/agents@env.agents.goal0:
- object_sphere_textured_goal
- point_textured
- point_seeker_random
- override /env/agents@env.agents.adversary0:
- object_sphere_textured_adversary
- point_textured
- point_seeker_random
env:
agents:
goal0:
trainable: false
overlay_color: [0.2, 0.8, 0.2, 1]
adversary0:
trainable: false
overlay_color: [0.8, 0.2, 0.2, 1]