Detection Task¶
The detection task is designed to train the agent to perform object discrimination. There are two objects in the environment, a goal object and an adversarial object, A screenshot of the agent’s view is shown below:
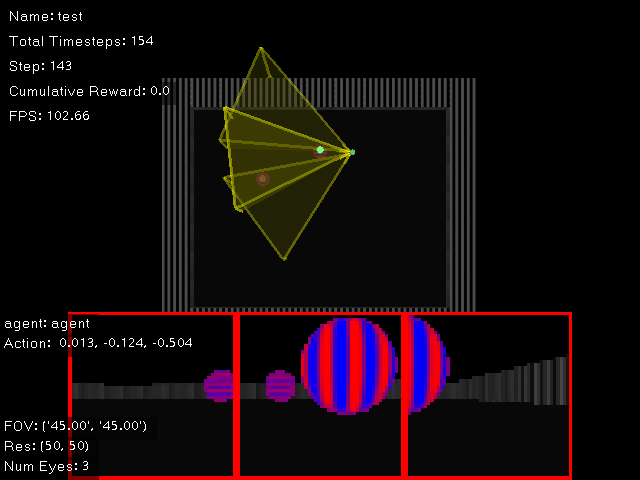
Screenshot of the detection task. The detection task incorporates two objects, a goal object and an adversarial object. The goal (visualized with a green dot above in the birds eye view) has vertical stripes. Conversely, the adversarial object (visualized with a red dot) has horizontal stripes. The green and red dots are not visible to the agent. The first person view of the agent is shown at the bottom of the image. In this screenshot, the agent has three eyes, each with 50x50 pixels.¶
The goal object has vertical stripes, while the adversarial object has horizontal stripes. In order to succeed at the task, the agent must learn to discern between these two objects. The reward function is as follows:
\(R_{\text{Detection}}\) is the reward at time \(t\) for each task, \(\lambda\) is a scaling factor, \(x_t\) and \(x_{t-1}\) is the position of the agent at time \(t\) and \(t-1\) respectively, \(x_0\) is the initial position of the agent, and \(x_f\) is the position of the goal. The \(w\) variables are non-zero when certain conditions are met. \(w_g\) and \(w_a\) indicates the reward/penalty given for reaching the goal and adversary, respectively. \(w_c\) is the penalty for contacting a wall. In essence, the agent is incentivized to navigate to the goal as quickly as it can. During training, \(\lambda = 0.25\), \(w_g = 1\), \(w_a = -1\), and \(w_c = -1\). Additionally, when an agent reaches the goal or adversary, the episode terminates.
Training an Agent¶
To train an agent on the detection task, you can use the following command:
bash scripts/run.sh cambrian/main.py --train example=detection
A successfully trained agent may look like the following:
Evaluating an Agent¶
You can evaluate a trained policy or the task itself in a few ways.
Evaluating using an Privileged Policy¶
We provide a simple policy that demonstrates good performance in the detection task. The policy is privileged in the sense that it has access to all environment states. The logic is defined in the MjCambrianAgentPointSeeker class. To evaluate using this policy, you can use the following command:
bash scripts/run.sh cambrian/main.py --eval example=detection env/agents@env.agents.agent=point_seeker
This command will save the evaluation results in the log directory, which defaults to logs/<today's date>/detection/.
Tip
You can also visualize the evaluation in a gui window by setting env.renderer.render_modes='[human]'. You may also need to set the environment variable MUJOCO_GL=glfw to use the window-based renderer.
Evaluating using a Trained Policy¶
You can also evaluate a trained policy using the trainer/model=loaded_model argument.
bash scripts/run.sh cambrian/main.py --eval example=detection trainer/model=loaded_model
This command will save the evaluation results in the log directory, as well.
Evolving an Agent¶
You can also evolve an agent using the following command:
sbatch scripts/run.sh cambrian/main.py --train task=detection evo=evo hydra/launcher=supercloud evo/mutations='[num_eyes,resolution,lon_range]' -m
This command will launch the individual scripts using submitit, with configurations defined in the configs/hydra/launcher/supercloud.yaml file. This file can be amended to work for other Slurm clusters.
Additionally, this command enables 3 types of mutations: num_eyes, resolution, and lon_range. Additional mutations can be added by modifying the evo/mutations argument.
The optimized configuration and its trained policy is shown below:
Task Configuration¶
# @package _global_
# This task is similar to light_seeking, but has a goal _and_ adversary. The
# config must set `custom.frequency` to the frequency of the texture
# that should be applied to the objects. By default, the textures are synchronized
# between the goal and adversary, but this can be overridden by setting
# env.agents.<object name>.custom.frequency directly for each object.
defaults:
# Use one maze for the time being
- /env/mazes@env.mazes.maze: OPEN
# Use the maze_task config as the base
- maze_task
# Define one point agent with a single eye
- /env/agents@env.agents.agent: point
- /env/agents/eyes@env.agents.agent.eyes.eye: multi_eye
# Define two objects: a goal and an adversary
- /env/agents@env.agents.goal0: object_sphere_textured_goal
- /env/agents@env.agents.adversary0: object_sphere_textured_adversary
custom:
# This sets both the frequency of the texture of the goal and adversary
# The goal and adversary textures are the same, just rotated 90 degrees relative
# to one another
frequency: 8
env:
mazes:
maze:
scale: 2.0
agent_id_map:
default: ${glob:agent*,${oc.dict.keys:env.agents}}
O: ${glob:goal*|adversary*,${oc.dict.keys:env.agents}}
reward_fn:
reward_if_done:
_target_: cambrian.envs.reward_fns.reward_fn_done
_partial_: true
scale_by_quickness: true
termination_reward: 1.0
truncation_reward: ${eval:'-${.termination_reward}'}
disable_on_max_episode_steps: true
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
penalize_if_has_contacts:
_target_: cambrian.envs.reward_fns.reward_fn_has_contacts
_partial_: true
reward: -1.0
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
truncation_fn:
truncate_if_close_to_adversary:
_target_: cambrian.envs.done_fns.done_if_close_to_agents
_partial_: true
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
to_agents: ${glob:adversary*,${oc.dict.keys:env.agents}}
distance_threshold: 1.0
termination_fn:
terminate_if_close_to_goal:
_target_: cambrian.envs.done_fns.done_if_close_to_agents
_partial_: true
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
to_agents: ${glob:goal*,${oc.dict.keys:env.agents}}
distance_threshold: 1.0
eval_env:
step_fn:
# respawn the goal or adversary if the agent is close to it
# this subsequently means that agents which avoid the adversary more often are
# far more likely to be selected for (i.e. they are better agents)
respawn_objects_if_agent_close:
_target_: cambrian.envs.step_fns.step_respawn_agents_if_close_to_agents
_partial_: true
for_agents: ${glob:goal*|adversary*,${oc.dict.keys:env.agents}}
to_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
distance_threshold: 1.0
reward_fn:
reward_if_goal_respawned:
_target_: cambrian.envs.reward_fns.reward_fn_agent_respawned
_partial_: true
# large positive reward for respawning the goal (which happens if the agent is
# close to it)
reward: 10.0
for_agents: ${glob:goal*,${oc.dict.keys:env.agents}}
scale_by_quickness: true
penalize_if_adversary_respawned:
_target_: cambrian.envs.reward_fns.reward_fn_agent_respawned
_partial_: true
# large negative reward for respawning the adversary (which happens if the agent
# is close to it)
reward: -20.0
for_agents: ${glob:adversary*,${oc.dict.keys:env.agents}}
scale_by_quickness: true
penalize_if_has_contacts:
# large negative reward for contacts
reward: -2.0
truncation_fn:
truncate_if_close_to_adversary:
disable: True
termination_fn:
terminate_if_close_to_goal:
disable: True