Navigation Task¶
The navigation task is designed to train an agent to orient itself in a map-like environment. The agent is spawned at one end of a map and is tasked to navigate as far as it can get through the corridor-like world to reach the other end.
Screenshot of the navigation task. The agent is spawned at the right end of the map in two possible locations (with small permutations to remove deterministic behavior). The agent must then navigate to the left while avoiding contact with walls using only visual stimuli.¶
The reward function is as follows, where the agent is rewarded for moving towards the end and penalized for contacting walls:
\(R_{\text{Navigation}}\) is the reward at time \(t\) for each task, \(\lambda\) is a scaling factor, \(x_t\) and \(x_{t-1}\) is the position of the agent at time \(t\) and \(t-1\) respectively, \(x_0\) is the initial position of the agent, and \(x_f\) is the position of the goal. The \(w\) variables are non-zero when certain conditions are met. \(w_g\) and \(w_a\) indicates the reward/penalty given for reaching the goal and adversary, respectively. \(w_c\) is the penalty for contacting a wall. In essence, the agent is incentivized to navigate to the goal as quickly as it can. During training, \(\lambda = 0.25\), \(w_g = 1\), \(w_a = -1\), and \(w_c = -1\). Additionally, when an agent reaches the goal or adversary, the episode terminates.
Training/Evaluation/Evolving an Agent¶
The training, evaluation, and evolution of an agent for the navigation task is identical to the detection task, except the task=navigation. Please refer to the Detection Task for more information. To enable a privileged agent, you should specify the agent as ...agent=point_seeker_maze instead of ...agent=point_seeker so that the policy avoids the maze walls.
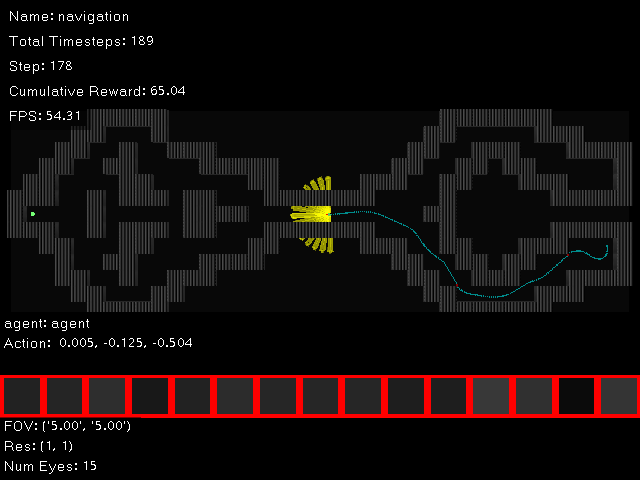
Below is an example of a successfully trained agent on the navigation task:
Below is an example of a privileged agent evaluation on the navigation task:
Evolving an Agent¶
You can also evolve an agent using the following command (similar to the Detection Task)
sbatch scripts/run.sh cambrian/main.py --train task=navigation evo=evo hydra/launcher=supercloud evo/mutations='[num_eyes,resolution,lon_range]' -m
The optimized configuration and its trained policy is shown below:
Task Configuration¶
# @package _global_
# This task is for navigation. It defines a set of mazes which the agent must navigate.
# The agent is rewarded based on it's movement from its initial position. The agent
# is penalized if it makes contact with the walls of the maze. A
# termination condition indicates success, and in this case, the agent is successful if
# it reaches the goal (within a certain distance threshold).
defaults:
# Use one fairly complicated maze
- /env/mazes@env.mazes.maze: COMPLEX
# Use the maze_task config as the base
- maze_task
# Define one point agent with a single eye
- /env/agents@env.agents.agent: point
- /env/agents/eyes@env.agents.agent.eyes.eye: multi_eye
# Define one goal object
- /env/agents@env.agents.goal: object_sphere
env:
agents:
goal:
custom:
size: 0.25
# Update the scale of the maze so that it's more difficult
mazes:
maze:
agent_id_map:
default: ${glob:agent*,${oc.dict.keys:env.agents}}
E: ${glob:agent*,${oc.dict.keys:env.agents}}
O: ${glob:goal*,${oc.dict.keys:env.agents}}
reward_fn:
reward_if_done:
_target_: cambrian.envs.reward_fns.reward_fn_done
_partial_: true
termination_reward: 1.0
truncation_reward: ${eval:'-${.termination_reward}'}
disable_on_max_episode_steps: true
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
scale_by_quickness: true
euclidean_delta_to_goal:
_target_: cambrian.envs.reward_fns.reward_fn_euclidean_delta_to_agent
_partial_: true
reward: 0.1
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
to_agents: ${glob:goal*,${oc.dict.keys:env.agents}}
penalize_if_has_contacts:
_target_: cambrian.envs.reward_fns.reward_fn_has_contacts
_partial_: true
reward: -0.1
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
truncation_fn:
truncate_if_low_reward:
_target_: cambrian.envs.done_fns.done_if_low_reward
_partial_: true
threshold: -50.0
termination_fn:
terminate_if_close_to_goal:
_target_: cambrian.envs.done_fns.done_if_close_to_agents
_partial_: true
for_agents: ${glob:agent*,${oc.dict.keys:env.agents}}
to_agents: ${glob:goal*,${oc.dict.keys:env.agents}}
distance_threshold: 1.0
eval_env:
mazes:
maze:
agent_id_map:
# Update the default map such that the agent is only placed on R:E spaces
default: []
reward_fn:
reward_if_done:
termination_reward: 10.0
euclidean_delta_to_goal:
reward: 2.0
penalize_if_has_contacts:
reward: -1.0
truncation_fn:
truncate_if_low_reward:
disable: true